Top Quality Type Error Messages
This chapter provides a gentle introduction to type systems, functional languages, and type error messages. We give examples of reported type error messages to illustrate the problems one typically has to face when programming in a statically typed language, such as Haskell. To improve the quality of type error messages, we introduce the Top type inference framework. An outline of the topics covered by this framework is given.
1. Introduction
Flaws in computer software are a fact of life, both in small and large-scale applications. From a user's perspective, these errors may take the form of crashing programs that quit unexpectedly, security holes in computer systems, or internet pages that are inaccessible due to scripting errors. In some cases, a malfunctioning application is only a nuisance that frustrates the user, but in other cases such an error may have severe consequences. Creating reliable programs is one of the most challenging problems for the software industry.
Some programming mistakes, such as division by zero, are generally detected dynamically, that is, while a program is being executed. Dynamic checks, often inserted by a compiler, offer the programmer a high degree of freedom: programs are always accepted by the compiler, but at the expense of leaving potential errors unexposed. Some errors are found by testing, but testing alone, even if done thoroughly, cannot guarantee the reliability of software.
Compilers for modern programming languages accommodate many program analyses for finding mistakes at compile-time, or statically. These analyses detect a significant portion of errors automatically: this makes program analyses a valuable and indispensable tool for developing high quality software. Static analysis gives us two major advantages: certain classes of errors are completely eliminated, and the immediate compiler feedback to the programmer increases efficiency in program development. Moreover, the programmer (rather than the user) is confronted with his own mistakes.
Type checking is perhaps the most popular and best studied form of static analysis. This analysis guarantees that functions (or methods) are never applied to incompatible arguments. This property is best summarized by Milner's well-known phrase "Well-typed programs do not go wrong" [42]. Type checking is traditionally an important part of functional programming languages.
Functional programming is an alternative paradigm for the widely-used imperative style of programming. In a functional language, a program is described by a collection of mathematical functions, and not by a sequence of instructions. Functional languages are based on the lambda calculus, which allows for a high degree of abstraction. Examples of functional programming languages are LISP, Scheme, and ML. More recently, the language Haskell was designed (named after the logician Haskell Curry). One common feature of ML and Haskell is that they are implicitly typed: no type annotations in the program are required, although both languages allow specifying types for parts of a program. Instead, these languages rely on an effective type inference algorithm, which automatically deduces all types. This inference algorithm has the pleasing property that it finds principal (or most general) types. In fact, the inference algorithm not only recovers type information, it also detects type inconsistencies in programs, which are generally caused by mistakes made by the programmer.
In most compilers, the algorithm for type inference is not designed to provide good feedback, but rather focuses on performance. The type error messages that are reported by these algorithms can be difficult to understand. For experienced programmers, this is not a problem. They are mainly interested in whether the program is well-typed or not, and may have the tendency to take only a brief look at error messages. Beginning programmers, on the other hand, may get the impression that they have to fight the type system before they can execute their programs. Their main concern is where and how the program should be corrected, which is not always clear from the error message. This makes static typing a double-edged sword: it is highly appreciated by experts, but it can easily become a source of frustration for inexperienced programmers. As a result, functional languages have a steep learning curve, which is a serious barrier to start appreciating functional programming. This thesis is entirely devoted to type inference for programming languages such as Haskell, and to the process of notifying a programmer about type errors in particular.
But why is it so difficult for compilers to report constructive type error messages? Haskell, for example, hosts a number of features that pose extra challenges for type recovery algorithms, and thus also for error reporting. First of all, it supports higher-order functions (a function can be passed as an argument to a function, and can be the result of a function), and functions are allowed to be curried: instead of supplying all arguments at once, we may supply one argument at a time. Furthermore, the types inferred for functions may be parametrically polymorphic: type variables represent arbitrary types. And, finally, absence of type information in a program may lead to a mismatch between the types inferred by the compiler and the types assumed by the programmer.
Our goal is to improve type error messages for higher-order, polymorphic programming languages, especially targeted to the beginning programmer. To a great extent, this boils down to management of information: having more information available implies being able to produce more detailed error reports. Ideally, we should follow a human-like inference strategy, and depart from the mechanical order in which standard inference algorithms proceed. This entails, for example, a global analysis of a program, which depends on heuristics that capture expert knowledge. We may even anticipate common errors and provide additional information for special classes of mistakes.
We have reached the above results by pursuing a constraint-based approach to type inference. The typing problem is first mapped to a set of type constraints, which is then passed to a specialized constraint solver.
Other researchers have addressed the problem of type error messages (Chapter 3 provides an overview of related work), but our approach distinguishes itself by the following characteristics.
- Practical experience. All type inference techniques have been implemented in the Helium compiler [26], which covers almost the entire Haskell 98 standard (see also Section 2.5 on Haskell implementations). This compiler has been used for the introductory functional programming courses at Utrecht University, by students without any prior knowledge of functional programming. The feedback received from the students helped to further enhance our inference techniques. The implementation affirms that our approach scales to a full-blown programming language.
- Customizable. There is no best type inference algorithm that suits everyone. Instead, we present a parameterized framework, which can be instantiated and customized according to one's personal preferences.
- Scriptable. The type inference process can be personalized even further by scripting the type inference process. A small special purpose language is presented to influence the inference process and change the error message facility, without losing soundness of the underlying type system. For instance, we can tune the error messages to the level of expertise of a specific group of programmers.
- Domain specific. Functional languages are very suitable for embedding domain specific languages (DSL), such as combinator libraries. Unfortunately, type error messages are typically reported in terms of the host language, and not in terms of the actual domain. The scripting facility that comes with our framework makes it possible to phrase error messages in terms of the specific domain, creating a close integration of the DSL and the host language.
1.1 Motivating examples
We present three examples to illustrate what kind of error messages are typically reported for incorrect programs, and we discuss why these reports are hard to comprehend. Although our examples are written in Haskell, the type error messages are characteristic for all programming languages with a type system that is based on the Hindley-Milner type rules. These rules will be discussed in the next section.
Example 1.1.
Let plus be the addition function with the type Int -> Int -> Int. We define a function f, which given a list of integers returns a pair consisting of the length and the sum of the list.f :: [Int] -> (Int, Int) f = \xs -> (length xs, foldr plus xs)
(a -> b -> b) -> b -> [a] -> b
ERROR "A.hs":2 - Type error in application *** Expression : length xs *** Term : xs *** Type : Int *** Does not match : [a]
The error message reveals that at some point during type inference, xs is assumed to be of type Int. In fact, this assertions arises from the application foldr plus xs. Note that the bias in this type error message is caused by the fact that the second component of a pair is considered before the first component, which is rather counterintuitive.
Example 1.2.
Function g computes the sine of the floating-point number 0.2, and multiplies the outcome with some parameter r. However, we make a syntax error in writing the floating-point number.g r = r * sin .2
g :: forall b a . (Num (a -> b), Floating b) => (a -> b) -> a -> b
In contrast with GHC, the Hugs interpreter does report a type error message for the definition of g.
ERROR "B.hs":1 - Illegal Haskell 98 class constraint in inferred type *** Expression : g *** Type : (Num (a -> b), Floating b) => (a -> b) -> a -> b
Example 1.3.
Not only beginning Haskell programmers suffer from inaccurate type error messages. The more complex functions and their types become, the more difficult it is to extract useful information from a type error report. For instance, consider the following error message by Hugs. (We are not interested in the program which resulted in this error message.)ERROR "C.hs":6 - Type error in application *** Expression : semLam <$ pKey "\\" <*> pFoldr1 (semCons,semNil) pVarid <*> pKey "->" *** Term : semLam <$ pKey "\\" <*> pFoldr1 (semCons,semNil) pVarid *** Type : [Token] -> [((Type -> Int -> [([Char],(Type,Int,Int))] -> Int -> Int -> [(Int,(Bool,Int))] -> (Doc,Type,a,b,[c] -> [Level],[S] -> [S])) -> Type -> d -> [([Char],(Type,Int,Int))] -> Int -> Int -> e -> (Doc,Type,a,b,f -> f,[S] -> [S]),[Token])] *** Does not match : [Token] -> [([Char] -> Type -> d -> [([Char],(Type,Int,Int))] -> Int -> Int -> e -> (Doc,Type,a,b,f -> f,[S] -> [S]),[Token])]
1.2 Overview of the framework
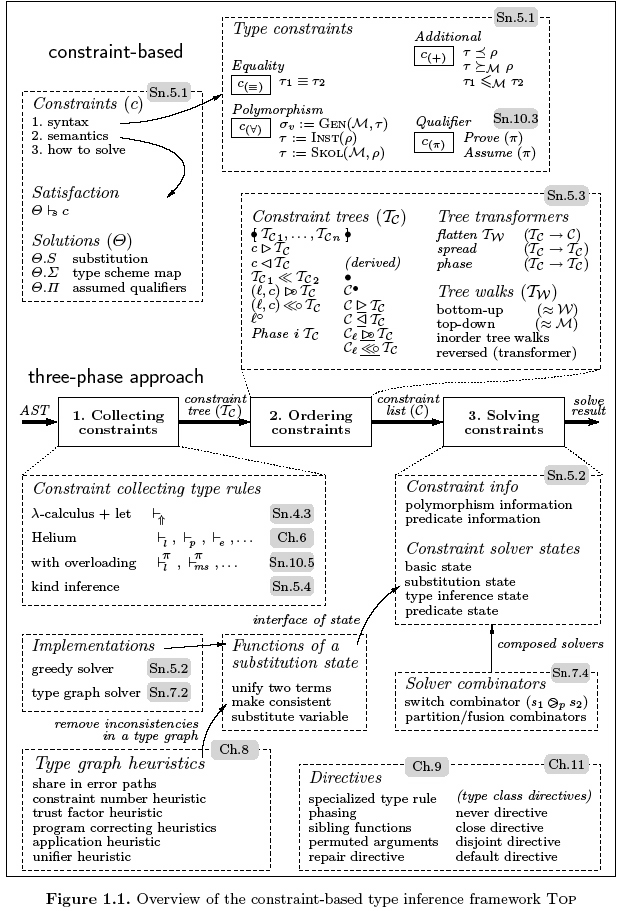
Figure 1.1 presents an overview of the constraint-based type inference framework Top, and gives correlations between the topics introduced in this thesis. For each topic, the figure indicates in which chapter or section it is discussed: these references are displayed in gray. Top is not only a theoretical framework, but also a library for building program analyses that offer high quality feedback to users.
Constraints play a central role in the framework, and in particular the set of type constraints that we use to describe the Haskell 98 type system. A type analysis conducted within the framework can be divided into three phases. Firstly, type constraints are collected for a program or an expression. For this, we use a set of syntax-directed constraint collecting type rules. These rules are formulated in a bottom-up fashion. In the second phase, we choose an ordering for the collected type constraints. If the constraints are inconsistent, then the relative order determines at which point we discover the error (in particular when the constraints are handled sequentially). Instead of collecting the type constraints in a set, we generate constraint trees that closely follow the shape of the abstract syntax tree of the program that is analyzed, and these trees are flattened using tree walks. As it turns out, the well-known type inference algorithms W and M (explained in Section 2.4) can be emulated by choosing a certain tree walk.
Thirdly, we discuss how to solve an ordered list of constraints. We take a flexible approach that allows new kinds of constraints to be included easily, and in which different solving strategies can live side by side. Special attention is paid to heuristics for dealing with type inconsistencies. These heuristics help to pinpoint the most likely source of a type error, and enhance the type error messages. Moreover, they can be used to give suggestions how to correct the problem (for a number of common mistakes).
In the Top framework, developers of a library can specify their own type inference directives. These directives are particularly useful in the context of domain specific languages. The directives change all three phases of the type inference process. For some directives we can guarantee that the underlying type system remains intact (i.e., it affects only the error reporting facility).
1.3 Structure of this thesis
Chapters 2 and 3 provide background material required for the remainder of the thesis. We introduce some notation, and give a short introduction to the Hindley-Milner type system, which is used in many modern programming languages. We explain the set of formal type rules, as well as two type inference algorithms that implement these rules. In Chapter 3, we give an extensive overview of the literature on type error messages, and we categorize all proposals.
A formal treatment of constraint-based type inference is given in the fourth chapter, and we explain how we deal with parametric polymorphism. Bottom-up type rules are used to collect constraints for a small expression language, and an algorithm to solve the constraints is discussed. We conclude this chapter with a correctness proof for our constraint-based approach with respect to the type rules formulated by Hindley and Milner.
We present an introduction to the Top type inference framework in Chapter 5, which is a continuation of the approach proposed in the previous chapter. Top is designed to be customizable and extendable, which are two essential properties to encourage reusability of the framework. In the Top framework, each constraint carries information, which can be used to create an error message if the constraint is blamed for a type inconsistency, and which describes properties of the constraint at hand. Three independent phases are distinguished: collecting constraints, ordering constraints, and solving constraints. Each of these phases is explained in detail. We conclude with a brief discussion on how to use the framework to perform kind inference, and we sum up the advantages of the approach taken.
Chapter 6 contains the complete set of constraint collecting type rules that is used by the Helium compiler [26]. Hence, these rules cover almost the entire Haskell 98 language. The most notable omission is that we do not consider overloading at this point. The rules are not only given for completeness reasons: they possess various strategies to enable high quality type error messages in later chapters. In fact, we use the rules to create a constraint tree for ordering the constraints in the second phase of the Top framework. The chapter includes a detailed presentation of binding group analysis.
Type graphs are introduced in Chapter 7. A type graph is a data structure for representing a substitution with the remarkable property that it can be in an inconsistent state. This property is the key to an alternative constraint solving algorithm, which can proceed in case of an inconsistency. With type graphs, we can efficiently analyze an entire set of type constraints, which significantly improves the quality of the type error messages. Finally, we introduce two combinators to compose constraint solvers.
Chapter 8 presents a number of predefined heuristics, which help to pinpoint the most likely source of an error. These heuristics work on the type graphs introduced in the previous chapter. In Chapter 9, we discuss type inference directives, which are user-defined heuristics. Directives enable a user to adapt the error reporting facility of a type system externally (that is, without changing the compiler). Directives are very suitable for experimenting with different type inference strategies, and are particularly useful to support domain specific libraries. Soundness of the presented directives is automatically checked, which is an important feature to guarantee that the underlying type system remains intact.
In Chapter 10, we extend the type inference framework to handle overloading of identifiers. We take an approach for dealing with qualifiers in general, which is closely related to Jones' theory on qualified types [31]. New constraints for dealing with qualifiers are added to the framework, and new constraint collecting type rules are given for the overloaded language constructs (to replace the rules from Chapter 6). We give a short introduction to improving substitutions, which are needed to capture other qualifiers.
Overloading of identifiers is a very pervasive language feature, and it strongly influences what is reported, and where. To remedy this problem, Chapter 11 proposes four type class directives to improve type error messages that are related to overloading. In addition, the directives from Chapter 9 are generalized to cope with overloading.
Finally, Chapter 12 sums up the main contributions of this thesis. We conclude with a list of topics that require further research.
References
| [18] | GHC Team. The Glasgow Haskell Compiler. http://www.haskell.org/ghc. |
| [26] | B. Heeren, D. Leijen, and A. van IJzendoorn. Helium, for learning Haskell. In Haskell'03: Proceedings of the ACM SIGPLAN Workshop on Haskell, pages 62-71. ACM Press, 2003. |
| [31] | M. P. Jones. Qualified Types: Theory and Practice. PhD thesis, University of Nottingham, November 1994. |
| [35] | M. P. Jones et al. The Hugs 98 system. OGI and Yale, http://www.haskell.org/hugs. |
| [42] | R. Milner. A theory of type polymorphism in programming. Journal of Computer and System Sciences, 17(3):348-375, August 1978. |